
Healthcare means a pool of data comprising a wealth of information. However, a maximum portion of this data is unstructured. In fact, 80% of the healthcare data is unstructured. They are in the form of clinical notes, patients’ narratives, and free-text records. Now, imagine the ply of clinicians to extract meaningful insights from this heap of unstructured data distributed across multiple medical devices. Here is where the need for an innovative solution knocks the door. Clinicians browse through various technologies that would serve the pressing need of handling massive volumes of data and its effective utilization to extract meaningful insights.
Enter Natural Language Processing (NLP) and Machine Learning (ML)!
NLP arms you with the capability to convert your unstructured data into a structured format. This structured text can easily be understood and interpreted by machines. However, your decision-making process requires the data to make sense of it. So, you must identify patterns or trends to make predictions and decisions based on these patterns. Here is where ML comes in. These two combinations are what clinicians require to craft personalized patient care.
Let us dive into how you can utilize NLP and ML.
Let us take an example of a patient’s record.
Patient: John Smith
Age: 45
Symptoms: Fever, cough, headache
Medical history: Allergic to penicillin
Diagnosis: Influenza
Treatment: Acetaminophen, plenty of fluids, rest
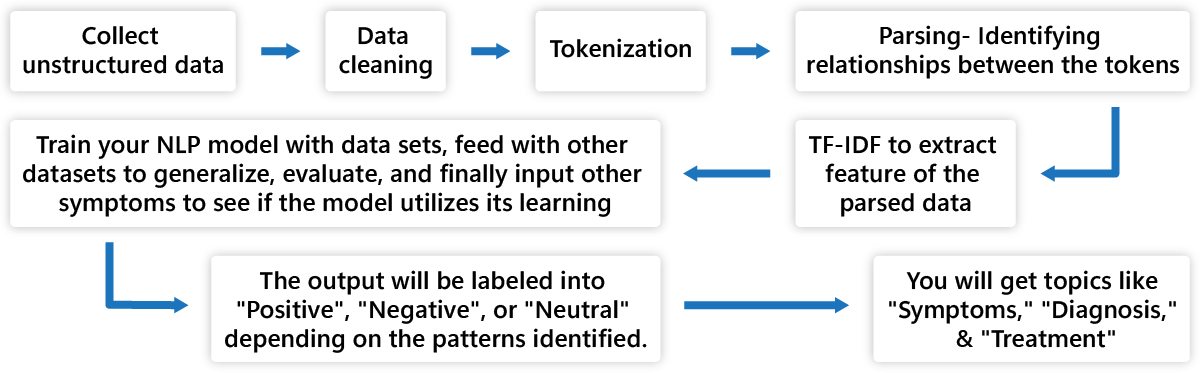
Step 1: Collect this unstructured data.
Step 2: Clean it by removing errors, space, or formatting issues.
Step 3: Break down these notes into individual words and phrases. These are called tokens. The tokenized data are as follows:
[“Patient”,”:”,”John”,”Smith”,”Age”,”:”,”45″,”Symptoms”,”:”,”Fever”,”cough”,”headache”,”Medical”,”history”,”:”,”Allergic”,”to”,”penicillin”,”Diagnosis”,”:”,”Influenza”,”Treatment”,”:”,”Acetaminophin”,”plenty”,”of”,”fluids”,”rest”]
Step 4: Now, identify the relationship between these words. These are parsed relationship. For example,
Patient: John Smith- Patient’s name is John Smith
Step 5: You have tokens and parsed relationships of these tokens. Now, start with feature extraction. In this process, you must convert these words into numeric that computers can work with. One of the popular methods is Term Frequency-Inverse Document Frequency (TF-IDF).
TF represents the number of occurrences of a word in the document, whereas IDF represents how rare a word appears in the same document. A word appearing repeatedly has a low IDF score.
TF-IDF is the product of TF and IDF scores.
For example, the word Penicillin occurs once in the document. So, TF will be 1. As, it is a unique, its IDF score will be high. Therefore, TF-IDF value for Penicillin will be high.
Step 6: It is time to train your NLP model. To train it, you will need similar medical notes. For example, you will train the model as when symptoms like “Fever,” “Cough,”, and “Headache” appear, the diagnosis will be influenza.
Similarly, for symptoms like “Headache” and “Fatigue”, the diagnosis will be Migraine. With such training data, the model starts learning the relationship between the symptoms and the diagnosis. Later, evaluate the model performance using separate data sets it has not fed with before. This process will help to generalize its learning to new cases. Finally, when your NLP model is trained and evaluated, input new symptoms, and you will see the model predicting the diagnosis based on its learning. Here the right ML algorithm is the key.
Step 7: The output of this may be into sentiments like “Positive”, “Negative”, or “Neutral.”
Step 8: The entities like “Penicillin” and “Influenza” will be highlighted as important entities.
Step 9: You will receive certain topics extracted from the text. In our example, you will receive “Symptoms”, “Diagnosis”, and “Treatment” as topics.
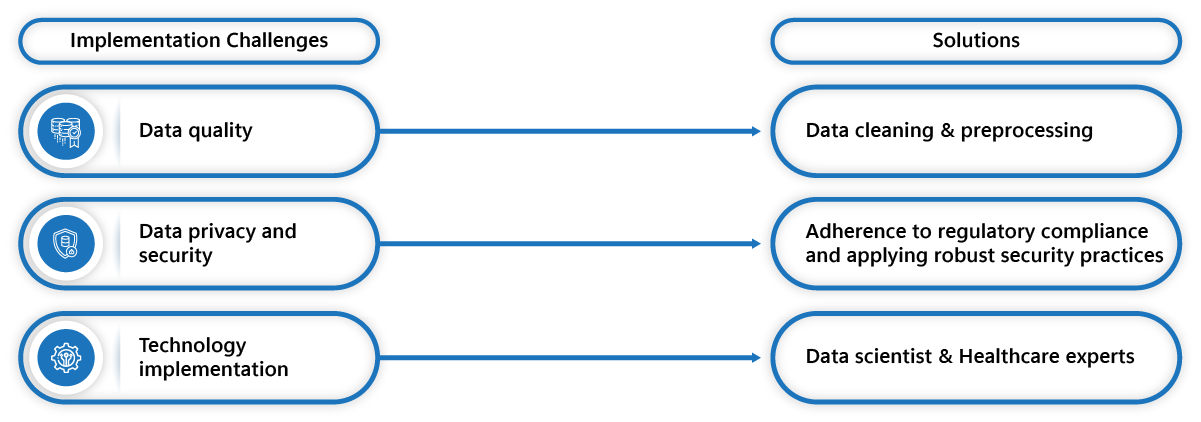
However, implementation comes with its challenges. The primary challenge is data quality. As the data is unstructured and gathered from various medical sources, the data can have abbreviations, errors, and inconsistencies. Another challenge is data privacy and security. While working with patients’ data, it is crucial to safeguard their privacy, so adhering to regulatory compliance while working on these data poses a challenge. Another challenge is technology implementation. NLP and ML require the collaboration of expert data scientists with their expertise in data analytics tools and clinicians to ensure accuracy and error-free processes.
Concisely, NLP and ML are a boon for clinicians. It can make sense of your clinical notes and patient narratives to give you actionable insights for better decision-making capabilities. This way, you can shape your patients’ journeys with you and achieve operational excellence. One of the best things you can do is partner with a data analytics company that has data analytics skills to help you lead the change toward a data-centric era. Although the ball is in your court now, while playing the winning shot in this data-driven healthcare, decide judiciously!
Top 4 FAQs on Healthcare data analytics
What is healthcare data analytics?
Healthcare data analytics involves capturing and analyzing health data for accurate and consistent information to draw actionable insights and drive better decision-making.
What is the role of NLP in healthcare data analytics?
NLP helps to convert the unstructured clinical data from various medical devices into structured formats to make more sense.
What are NLP applications in healthcare?
NLP applies in many domains like:
- Patient monitoring
- Clinical decision support
- Diagnosis
- Personalized patient care
- Research
- Administrative automation
- Operational excellence
What is the role of ML in clinical data?
ML learns from labeled clinical data to:
- Classify documents
- Make predictions
- Detect errors
- Cluster similar texts/documents