



Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Is your data pipeline slowing you down?
Making decisions quickly and with confidence hinges on how well you manage and utilize your data. But with growing volumes of data from multiple sources, maintaining efficiency can feel like trying to juggle too many things at once.
By leveraging metadata, you can transform how your data flows, making it not only more organized but also more powerful. Metadata is what allows you to manage, automate, and scale data processes across your organization.
In this blog, we’ll break down how metadata in Microsoft Fabric can supercharge your data pipelines, making them more agile, accurate, and efficient.
Metadata, in simple terms, refers to the data about the data. In the context of Microsoft Fabric, it’s the foundational information that helps define the structure, usage, and behavior of data within a data pipeline.
It governs how data is processed, ensures it’s secure and compliant, and helps automate many of the tasks that would otherwise require manual intervention. This allows businesses to manage their data pipelines more efficiently and scale their operations without losing control over their data quality.
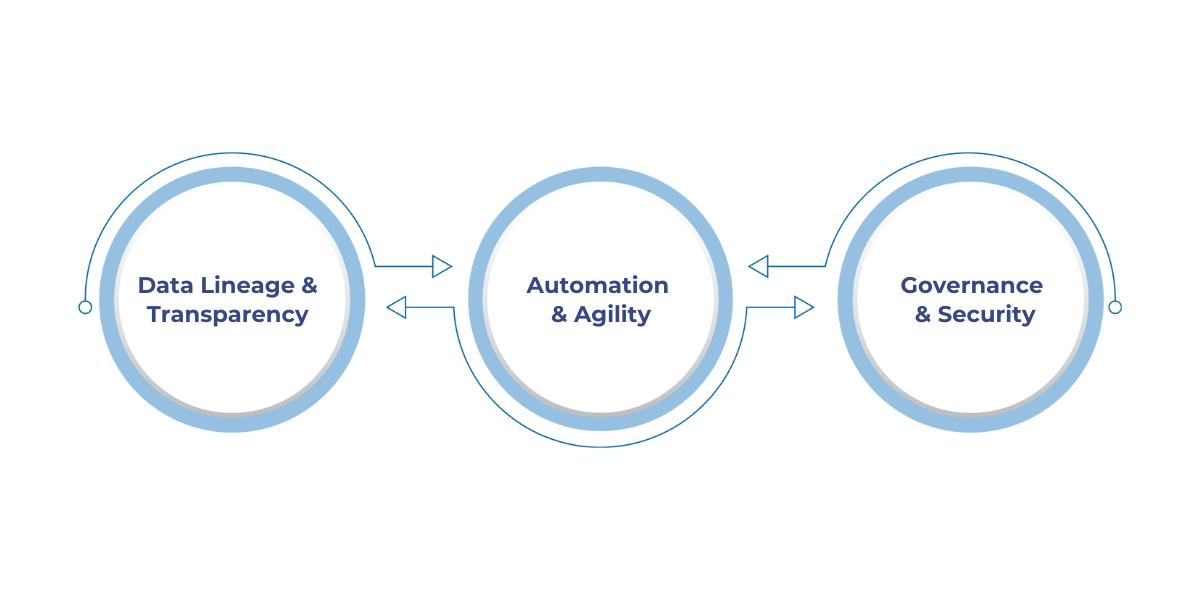
Fabric metadata ensures data integrity and governance, while enhancing transparency and decision-making:

By setting the foundation with metadata, businesses can now move into how this metadata plays a crucial role within data pipelines. Understanding the functionality of metadata in these pipelines is the next step to fully appreciating its value.
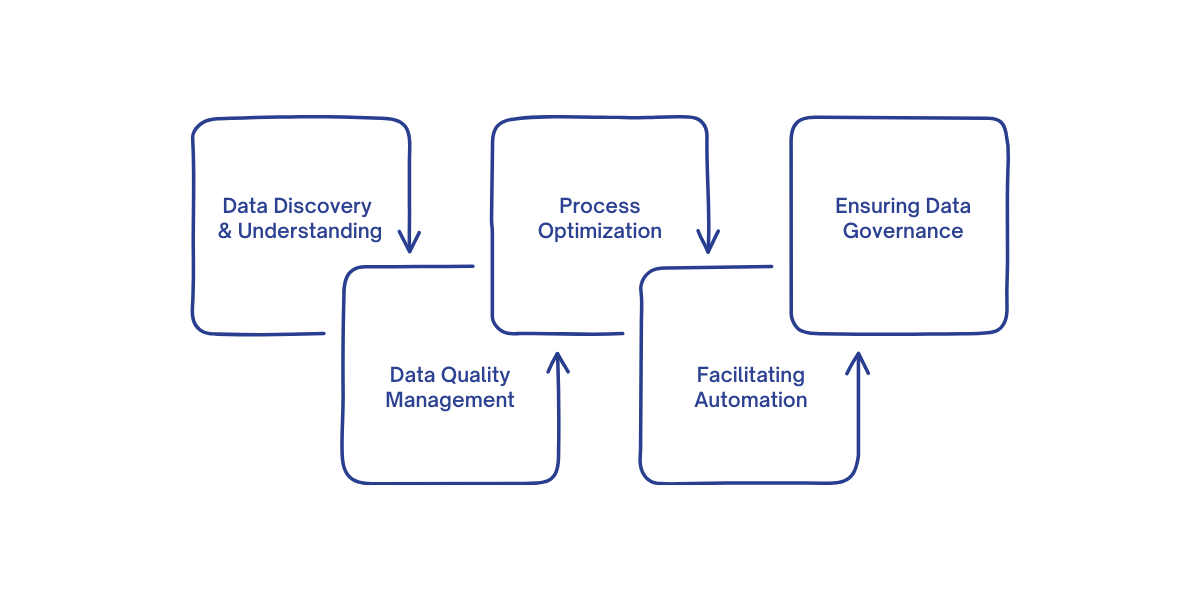
In Microsoft Fabric, metadata is crucial in managing and processing data. It enhances how data flows, ensuring efficiency, compliance, and optimization in data pipelines. Here's how:

With the proper governance mechanisms in place, metadata ensures that data is not only accessible but also secure, compliant, and auditable.
Suggested read: Fundamentals and Best Practices of Metadata Management
Now that we understand how metadata supports data flow and ensures quality, let's dive deeper into the key components of metadata-driven pipelines. This will help clarify how these elements work together to optimize data operations.
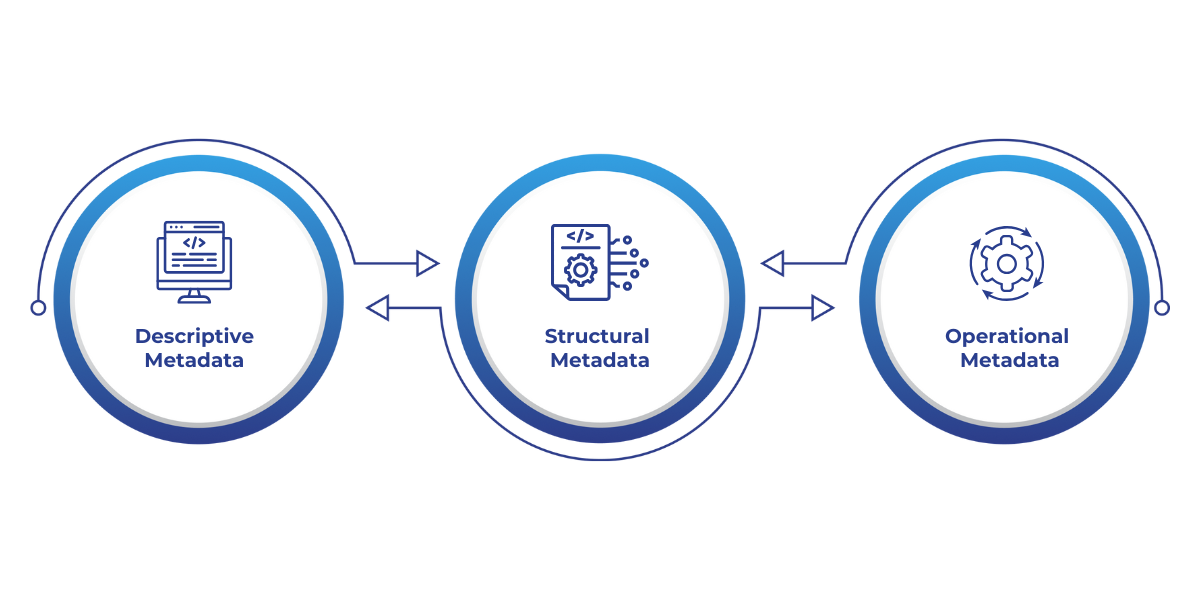
There are three main categories of metadata in Microsoft Fabric: Descriptive, Structural, and Operational metadata. Each type has its own unique function, contributing to the seamless management and execution of data pipelines.
Descriptive metadata is the most straightforward type. It provides basic information about the data, making it easier to understand and use. This metadata describes what the data is, helping users quickly identify, classify, and organize it.
Descriptive metadata is crucial for data discovery and accessibility. It helps analysts, data engineers, and other stakeholders quickly locate and understand the data they’re working with.
Structural metadata defines the organization and relationships of data within databases or other data systems. This type of metadata outlines how data is stored, linked, and formatted across different platforms, enabling better data organization and interaction.
Structural metadata is key to data modeling, ensuring that data flows correctly through different processes while maintaining integrity and accessibility.
Operational metadata provides information about the data's lifecycle and the operations performed on it. This type of metadata is critical for understanding the history, usage, and transformations that data has gone through within the pipeline.
Operational metadata is essential for data governance, ensuring that data transformations and movements are well-documented, traceable, and compliant with internal or external regulations.
Also read: Top Metadata Management Tools and Their Features
Having laid the groundwork for the structure of metadata-driven pipelines, the next step is to look at the practical steps to implement them. This approach will help you leverage these principles in real-life scenarios.
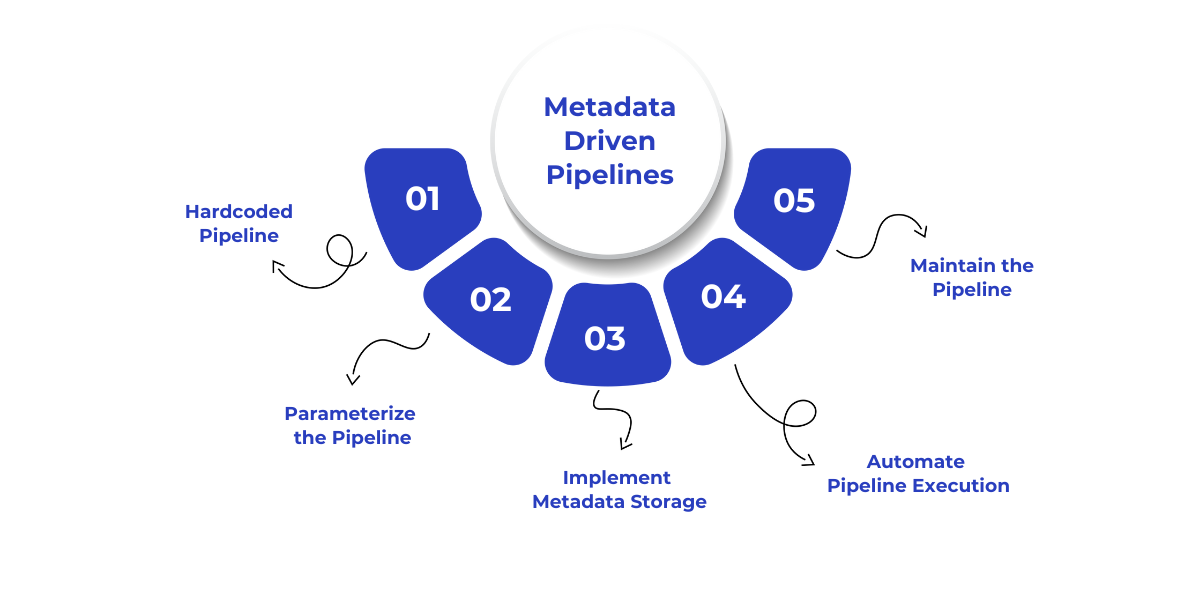
Building metadata-driven pipelines in Microsoft Fabric allows organizations to automate and scale their data integration processes efficiently. Here's a practical guide to implementing these pipelines:
Begin by creating a straightforward pipeline that copies a single table from a source to a destination, such as a data lakehouse. This initial step helps validate connections and configurations before introducing complexity.
Starting with a simple, hardcoded pipeline allows you to troubleshoot and confirm the basic setup before scaling.
Once the basic pipeline is working, introduce parameters to make it dynamic and reusable for multiple tables.
Parameterizing the pipeline enables you to reuse the same pipeline logic for different datasets, reducing redundancy.
To manage multiple tables efficiently, store metadata in a structured format, such as a JSON file or a database table.
Using a metadata store centralizes configuration and makes it easier to manage and update pipeline logic.
Enhance the pipeline's automation by incorporating activities that handle multiple tables sequentially.
Automation ensures that the pipeline can process numerous tables without manual intervention, improving efficiency.
After setting up the pipeline, focus on optimization and maintenance to ensure long-term success.
Regular optimization and maintenance keep the pipeline running smoothly and adaptable to changes.
Implementing metadata-driven pipelines in Microsoft Fabric is a strategic approach to modernizing your data infrastructure. By leveraging metadata, organizations can automate data workflows, enhance scalability, and ensure consistent data governance.
At WaferWire, we specialize in helping businesses build, optimize, and scale their data pipelines. Whether you're just starting with Microsoft Fabric or need expert guidance in implementing complex metadata-driven workflows, our team of experts is here to support you every step of the way. We offer comprehensive services, including:
If you're ready to unlock the full potential of your data with metadata-driven pipelines, contact WaferWire today. Let us help you navigate the complexities of Microsoft Fabric and build a data architecture that drives informed decision-making and business growth.
1. How does metadata-driven automation reduce operational costs in data pipelines?
By automating routine tasks like data validation and transformation, metadata-driven pipelines eliminate the need for manual intervention, reducing labor costs and improving overall operational efficiency.
2. What are the common challenges businesses face when integrating metadata into their data pipelines?
Businesses often face challenges like data inconsistency across platforms, the complexity of mapping legacy systems to modern metadata formats, and the need for specialized tools to manage and automate metadata workflows.
3. How can metadata be used to improve data accessibility in distributed systems?
Metadata helps standardize data formats and structures, making it easier to access and query data across distributed systems. It also enables the integration of data from different sources, providing a unified view of information.
4. What are the key benefits of using metadata to track and manage data transformations in a pipeline?
Tracking transformations via metadata provides greater transparency into data processing, enabling businesses to monitor the success of data operations, identify bottlenecks, and ensure that data is transformed consistently across pipelines.
5. Can metadata-driven pipelines be adapted to handle unstructured data?
Yes, metadata can be used to categorize and define unstructured data, such as text, images, or videos, allowing businesses to process it alongside structured data and apply the same automation and governance principles.



Is your data pipeline slowing you down?
Making decisions quickly and with confidence hinges on how well you manage and utilize your data. But with growing volumes of data from multiple sources, maintaining efficiency can feel like trying to juggle too many things at once.
By leveraging metadata, you can transform how your data flows, making it not only more organized but also more powerful. Metadata is what allows you to manage, automate, and scale data processes across your organization.
In this blog, we’ll break down how metadata in Microsoft Fabric can supercharge your data pipelines, making them more agile, accurate, and efficient.
Metadata, in simple terms, refers to the data about the data. In the context of Microsoft Fabric, it’s the foundational information that helps define the structure, usage, and behavior of data within a data pipeline.
It governs how data is processed, ensures it’s secure and compliant, and helps automate many of the tasks that would otherwise require manual intervention. This allows businesses to manage their data pipelines more efficiently and scale their operations without losing control over their data quality.
Fabric metadata ensures data integrity and governance, while enhancing transparency and decision-making:
By setting the foundation with metadata, businesses can now move into how this metadata plays a crucial role within data pipelines. Understanding the functionality of metadata in these pipelines is the next step to fully appreciating its value.
In Microsoft Fabric, metadata is crucial in managing and processing data. It enhances how data flows, ensuring efficiency, compliance, and optimization in data pipelines. Here's how:
With the proper governance mechanisms in place, metadata ensures that data is not only accessible but also secure, compliant, and auditable.
Suggested read: Fundamentals and Best Practices of Metadata Management
Now that we understand how metadata supports data flow and ensures quality, let's dive deeper into the key components of metadata-driven pipelines. This will help clarify how these elements work together to optimize data operations.
There are three main categories of metadata in Microsoft Fabric: Descriptive, Structural, and Operational metadata. Each type has its own unique function, contributing to the seamless management and execution of data pipelines.
Descriptive metadata is the most straightforward type. It provides basic information about the data, making it easier to understand and use. This metadata describes what the data is, helping users quickly identify, classify, and organize it.
Descriptive metadata is crucial for data discovery and accessibility. It helps analysts, data engineers, and other stakeholders quickly locate and understand the data they’re working with.
Structural metadata defines the organization and relationships of data within databases or other data systems. This type of metadata outlines how data is stored, linked, and formatted across different platforms, enabling better data organization and interaction.
Structural metadata is key to data modeling, ensuring that data flows correctly through different processes while maintaining integrity and accessibility.
Operational metadata provides information about the data's lifecycle and the operations performed on it. This type of metadata is critical for understanding the history, usage, and transformations that data has gone through within the pipeline.
Operational metadata is essential for data governance, ensuring that data transformations and movements are well-documented, traceable, and compliant with internal or external regulations.
Also read: Top Metadata Management Tools and Their Features
Having laid the groundwork for the structure of metadata-driven pipelines, the next step is to look at the practical steps to implement them. This approach will help you leverage these principles in real-life scenarios.
Building metadata-driven pipelines in Microsoft Fabric allows organizations to automate and scale their data integration processes efficiently. Here's a practical guide to implementing these pipelines:
Begin by creating a straightforward pipeline that copies a single table from a source to a destination, such as a data lakehouse. This initial step helps validate connections and configurations before introducing complexity.
Starting with a simple, hardcoded pipeline allows you to troubleshoot and confirm the basic setup before scaling.
Once the basic pipeline is working, introduce parameters to make it dynamic and reusable for multiple tables.
Parameterizing the pipeline enables you to reuse the same pipeline logic for different datasets, reducing redundancy.
To manage multiple tables efficiently, store metadata in a structured format, such as a JSON file or a database table.
Using a metadata store centralizes configuration and makes it easier to manage and update pipeline logic.
Enhance the pipeline's automation by incorporating activities that handle multiple tables sequentially.
Automation ensures that the pipeline can process numerous tables without manual intervention, improving efficiency.
After setting up the pipeline, focus on optimization and maintenance to ensure long-term success.
Regular optimization and maintenance keep the pipeline running smoothly and adaptable to changes.
Implementing metadata-driven pipelines in Microsoft Fabric is a strategic approach to modernizing your data infrastructure. By leveraging metadata, organizations can automate data workflows, enhance scalability, and ensure consistent data governance.
At WaferWire, we specialize in helping businesses build, optimize, and scale their data pipelines. Whether you're just starting with Microsoft Fabric or need expert guidance in implementing complex metadata-driven workflows, our team of experts is here to support you every step of the way. We offer comprehensive services, including:
If you're ready to unlock the full potential of your data with metadata-driven pipelines, contact WaferWire today. Let us help you navigate the complexities of Microsoft Fabric and build a data architecture that drives informed decision-making and business growth.
1. How does metadata-driven automation reduce operational costs in data pipelines?
By automating routine tasks like data validation and transformation, metadata-driven pipelines eliminate the need for manual intervention, reducing labor costs and improving overall operational efficiency.
2. What are the common challenges businesses face when integrating metadata into their data pipelines?
Businesses often face challenges like data inconsistency across platforms, the complexity of mapping legacy systems to modern metadata formats, and the need for specialized tools to manage and automate metadata workflows.
3. How can metadata be used to improve data accessibility in distributed systems?
Metadata helps standardize data formats and structures, making it easier to access and query data across distributed systems. It also enables the integration of data from different sources, providing a unified view of information.
4. What are the key benefits of using metadata to track and manage data transformations in a pipeline?
Tracking transformations via metadata provides greater transparency into data processing, enabling businesses to monitor the success of data operations, identify bottlenecks, and ensure that data is transformed consistently across pipelines.
5. Can metadata-driven pipelines be adapted to handle unstructured data?
Yes, metadata can be used to categorize and define unstructured data, such as text, images, or videos, allowing businesses to process it alongside structured data and apply the same automation and governance principles.






.svg)
